Hello!
I’ve just registered on the platform, and I’m running my first processes to test out the system. It works nicely both on the web editor and via Python API, but I got worried by the large amount of credits required for a simple point sampling task.
Here’s my trivial test process: get time series of Vegetation Indices for N pixels (point geometries) for year 2018

this is the equivalent Python code
dc_collection = connection.load_collection(collection_id = "VEGETATION_INDICES", spatial_extent = {"west": 8.058428808185612, "east": 9.90150590839975, "south": 38.82259352166011, "north": 41.291280668691115}, temporal_extent = ["2018-01-01T00:00:00Z", "2018-12-31T23:59:59Z"])
def reducer_first(data, context = None):
return process("first", data = data)
gdf_json = json.loads(gdf.to_crs(4326).sample(10).to_json())
vc_aggregation = dc_collection.aggregate_spatial(geometries = gdf_json, reducer = reducer_first)
vc_save = vc_aggregation.save_result(format = "NETCDF")
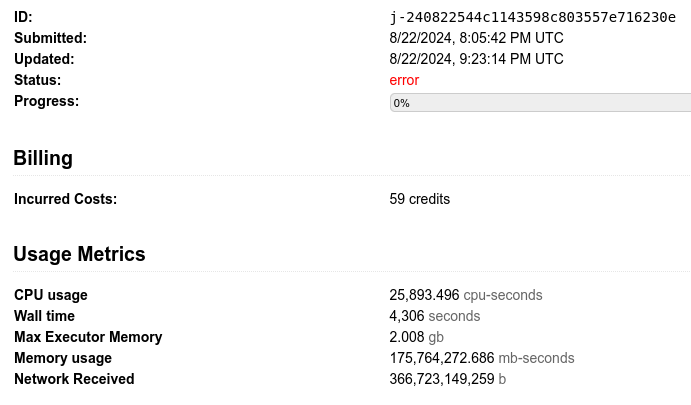
if N == 1 it requires 17 credits
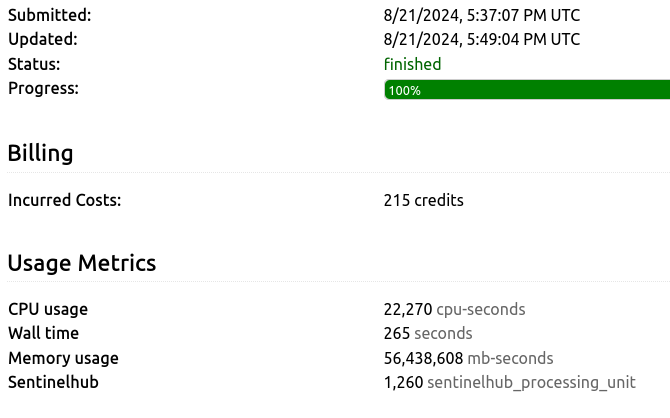
if N == 10 it requires 215 credits ![]()
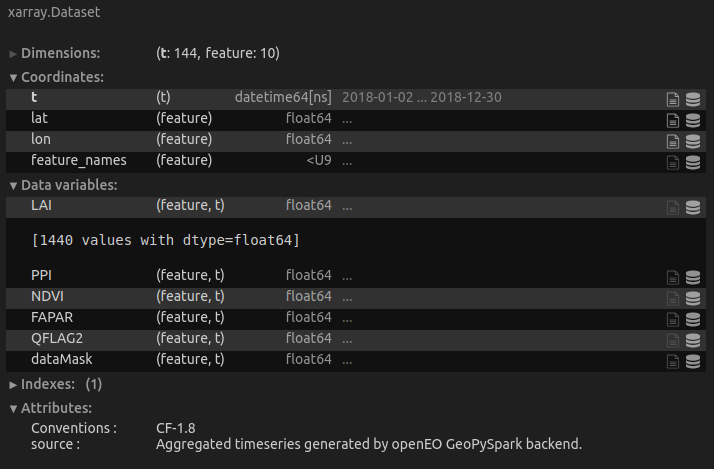
In both cases the result is correct.
Considering that the 10 points are spanned over just 2 sentinel tiles, I was expecting to see cost to double up and then don’t increment much more, but I got a x12.5 credits cost increment.
Considering that I will need to sample 50k points in same area and that GEE does that quite easily, I think I’m doing something wrong, as it would be 1075000 credits, and that would be quite a lot of money ![]()

Could you please explain me if my algorithm is correct? I’m bounding the load_collection both in space and time, and I tried using filter_spatial instead of aggregate_spatial but I got false positives (process finished successfully, but downloading result is a HTTP 404, but credit are consumed)
Thanks