Hey all,
There are two raster:
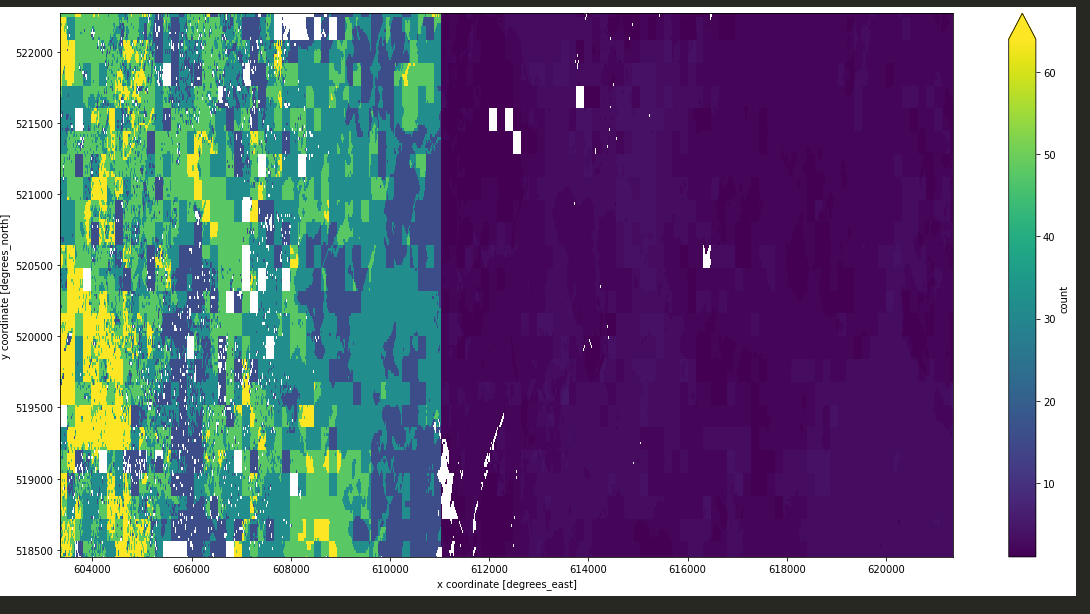
1st raster: s2_cube_water_sum:
2nd raster: s2_count:
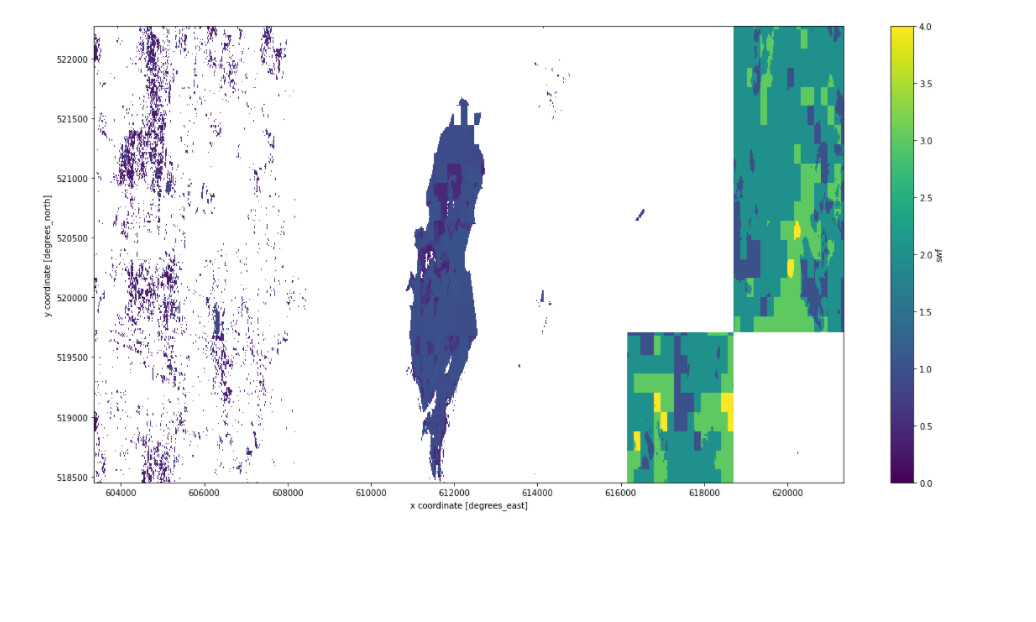
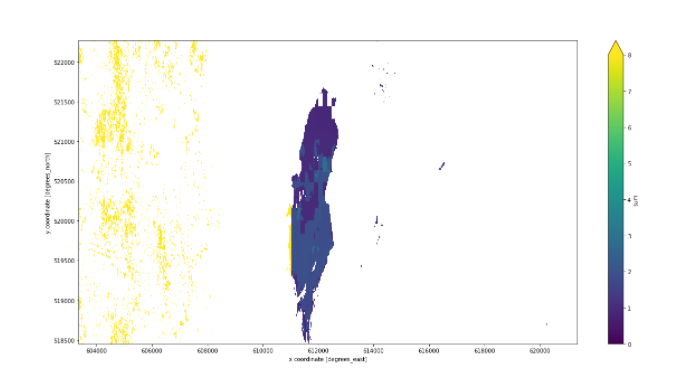
When we divided raster by raster: s2_cube_swf = s2_cube_water_sum / s2_count, the output shows some unexpected blocks on the right side. Do you know why this happens?
ID: j-8d5a45a6ad674b128eaa196eb60cf416
Hi Andrea,
I’m thinking this might happen if either one of the cubes has no tiles or nodata tiles in those areas.
We might be able to solve it by doing the various steps within the same cube, like we did to solve the memory use of the masking operation.
I can have a look if you have the python snippet that generates this result?
thanks,
Jeroen
start_date = '2021-05-01'
start_date_dt_object = datetime.strptime(start_date, '%Y-%m-%d')
end_date = (start_date_dt_object + relativedelta(months = +1)).date()
start_date_exclusion = (start_date_dt_object + relativedelta(months = -2)).date()
spatial_extent = {'west': -74.06910760, 'east': -73.80597343, 'south': 4.689864510, 'north': 4.724080996, 'crs': 'epsg:4326'}
bands = ['B02', 'B03', 'B04', 'B08', 'CLP', 'SCL' , 'sunAzimuthAngles', 'sunZenithAngles']
## Get the Sentinel-2 data for a 3 month window.
s2_cube = connection.load_collection(
'SENTINEL2_L2A_SENTINELHUB',
spatial_extent = spatial_extent,
temporal_extent = [start_date_exclusion, end_date],
bands = ['B02', 'B03', 'B04', 'B08', 'CLP', 'SCL', 'sunAzimuthAngles']
)
scl = s2_cube.band("SCL")
mask_scl = (scl == 3) | (scl == 8) | (scl == 9) | (scl == 10) |(scl == 11)
s2_cube = s2_cube.mask(mask_scl)
clp = s2_cube.band("CLP")
mask_clp = (clp / 255) > 0.3
s2_cube = s2_cube.mask(mask_clp)
s2_count = s2_cube.filter_bands(bands = ["B08"])
s2_count = s2_count.reduce_dimension(reducer=lambda data: data.count(), dimension = "t")
s2_count = s2_count.add_dimension("bands", "count", type = "bands")
s2_cube = append_index(s2_cube,"NDWI") ## index 7
s2_cube = append_index(s2_cube,"NDVI") ## index 8
def water_function(data):
ndwi = array_element(data, index = 7)
ndvi = array_element(data, index = 8)
water = 1 / (1 + exp(- (0.845 + (2.14 * ndvi) + (13.5 * ndwi))))
return water
s2_cube_water = s2_cube.reduce_dimension(reducer = water_function, dimension = "bands")
s2_cube_water = s2_cube_water.add_dimension("bands", "water_prob", type = "bands")
s2_cube_water_threshold = s2_cube_water.apply_dimension(dimension="bands", process=lambda x: if_(x > 0.75, x))
s2_cube_water_threshold = s2_cube_water_threshold.add_dimension("bands", "w_T75", type = "bands")
s2_cube_water_sum = s2_cube_water_threshold.reduce_dimension(reducer = "sum", dimension = "t")
s2_cube_water_sum = s2_cube_water_sum.add_dimension("bands", "sum", type = "bands")
s2_cube_swf = s2_cube_water_sum / s2_count
s2_cube_swf = s2_cube_swf.add_dimension("bands", "swf", type = "bands")
@stefaan.lippens
Could you have a look please?
This is another example use case for "Overlap-only" mode for merge_cubes · Issue #280 · Open-EO/openeo-processes · GitHub
The division operation
s2_cube_swf = s2_cube_water_sum / s2_count
is implemented with merge_cubes and and overlap resolver that implements the division.
This works properly for sections of bbox where both are s2_cube_water_sum and s2_count are non-null.
However if you have blocks where where s2_cube_water_sum is completely null or NaN, then the overlap resolver is not used and you get just
s2_cube_swf = s2_count
Likewise, in blocks where s2_count is completely null/NaN, the result is
s2_cube_swf = s2_cube_water_sum
I think this is what you are seeing here.
The current workaround is making sure both s2_cube_water_sum and s2_count are masked in the same way. Or use that mask to postprocess s2_cube_swf after division to hide the parts that are unintended.
I hope this makes sense
Yes, it makes sense and It works now. Thanks for supporting us with this