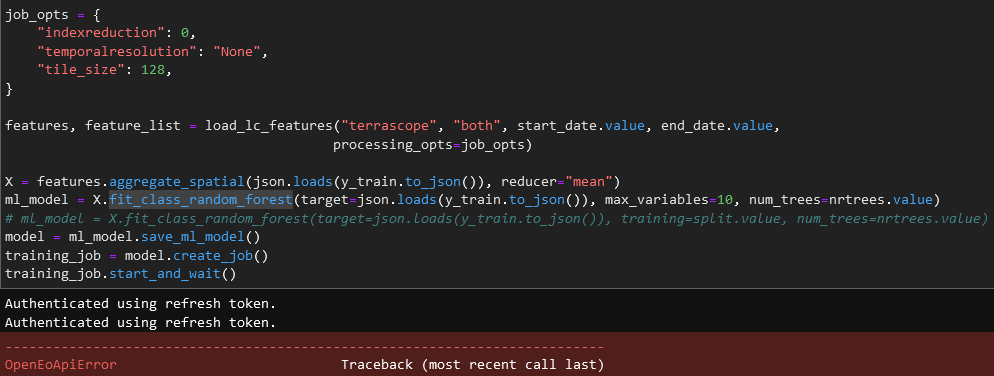
When attempting to train a RF model (in this case using the UC9 notebook) I get the following error: OpenEoApiError: [413] Internal: 413 Request Entity Too Large: The data value transmitted exceeds the capacity limit. (ref: 78ef928f-3555-486e-9684-e250b5d7c8df)
Presumably this is related to a too large sampling area for the training… Now in this case I had already reduced that quite a bit (compared to the previous run)…
Is there any workaround for this? Should we give users some guidance on the volume of samples / sampling AOI for this type of use case?
Hi Patrick, yes this is indeed related to a too large sampling area for training. A workaround is not loading a json from file but by directly passing a geojson from a URL, for example from github, so that it doesn’t have to be loaded first client side and then passed to a backend but can be read straight away from a public URL by a backend.
I think in any case it’s good to give users some guidance in that perspective indeed, I will add some documentation on the volume of samples in the notebook.
The problem is indeed that the request you send to the backend is too large because of a large GeoJson feature collection. To make things worse, the feature collection is actually duplicated in the request because it’s used in aggregate_spatial and in fit_class_random_forest. It’s possible to avoid this duplication, but chances are still pretty high to hit some limit.
A better solution is making sure the geojson can be loaded from a URL, so that your request stays small.
An official process to enable this is still under discussion (api#322), but the VITO backend already has an experimental implementation read_vector (which supports loading vector data from URL).
So if you can host your geojson data on some URL, this is an experimental workaround:
# Example URL with geojson
url = "https://raw.githubusercontent.com/Open-EO/openeo-python-client/master/tests/data/polygon.json"
# Note: DataCube.aggregate_spatial() in Python client
# supports GeoJSON URL loading directly
X = features.aggregate_spatial(url, reducer="mean")
# Workaround to use GeoJSON URL in fit_class_random_forest
from openeo.processes import process
target = process("read_vector", filename=url)
ml_model = X.fit_class_random_forest(target=target, max_variables=10, ...
thanks for the feedback and the workaround instructions…
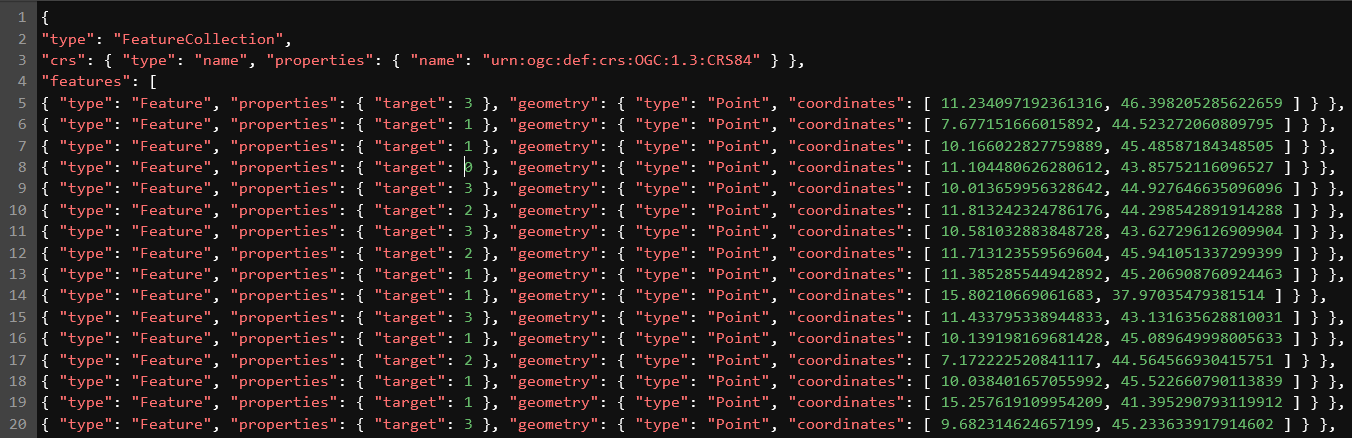
I converted the feature geometries (i.e. point from which to sample the EO data) to Geojson: y_train.to_file("/home/jovyan/(...)/y_json.json", driver="GeoJSON")
and then followed the suggested workaround with the “read_vector” process, which results in the below error:
OpenEoApiError: [500] Internal: Server error: JSONDecodeError('Expecting value: line 4 column 1 (char 3)') (ref: 5ad24cab-fcd3-4049-88a3-4117b0cc7571)
The formatting of the GeoJson looks fine to me - I also tried polishing it (removing blanks etc.) but it keeps results in errors:
thanks, I found that you are using something like this as geojson url: https://eolab.eodc.eu/hub/user-redirect/lab/tree/../resources/y_json3.json
But as far as I understand that URL requires authentication, so when the back-end tries to load that URL, it gets an HTML login page, which causes the JSONDecodeError error.
Can you make sure you use a public URL to share the geojson?
In the back-end we should also double check that the response has content type JSON (the URL above has content type “text/html” and we should complain about that instead of a more cryptic JSONDecodeError)
That’s indeed a non-informative error. Luckily in the logs I find more info:
File "/opt/venv/lib64/python3.8/site-packages/openeogeotrellis/backend.py", line 1317, in _scheduled_sentinelhub_batch_processes
actual_area = area()
File "/opt/venv/lib64/python3.8/site-packages/openeogeotrellis/backend.py", line 1311, in area
return (self._jvm
File "/usr/local/spark/python/lib/py4j-0.10.9.2-src.zip/py4j/java_gateway.py", line 1309, in __call__
return_value = get_return_value(
File "/usr/local/spark/python/lib/py4j-0.10.9.2-src.zip/py4j/protocol.py", line 326, in get_return_value
raise Py4JJavaError(
py4j.protocol.Py4JJavaError: An error occurred while calling o1048.areaInSquareMeters.
: org.locationtech.proj4j.ProjectionException: -21
at org.locationtech.proj4j.proj.AlbersProjection.initialize(AlbersProjection.java:126)
at org.locationtech.proj4j.parser.Proj4Parser.parseProjection(Proj4Parser.java:180)
at org.locationtech.proj4j.parser.Proj4Parser.parse(Proj4Parser.java:57)
at org.locationtech.proj4j.CRSFactory.createFromParameters(CRSFactory.java:127)
at org.locationtech.proj4j.CRSFactory.createFromParameters(CRSFactory.java:106)
at org.locationtech.proj4j.util.CRSCache.lambda$createFromParameters$1(CRSCache.java:52)
at java.base/java.util.concurrent.ConcurrentHashMap.computeIfAbsent(ConcurrentHashMap.java:1705)
at org.locationtech.proj4j.util.CRSCache.createFromParameters(CRSCache.java:52)
at geotrellis.proj4.CRS$$anon$1.<init>(CRS.scala:41)
at geotrellis.proj4.CRS$.fromString(CRS.scala:41)
at org.openeo.geotrellis.ProjectedPolygons$.org$openeo$geotrellis$ProjectedPolygons$$areaInSquareMeters(ProjectedPolygons.scala:167)
at org.openeo.geotrellis.ProjectedPolygons.areaInSquareMeters(ProjectedPolygons.scala:16)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
not sure yet what’s going on here, just posting it here, maybe it rings a bell for @jeroen.dries
Couldn’t investigate deeply, but I’m suspecting the problem might be triggered by the fairly large area that is covered by the points in this dataset.
One thing to try is to introduce a resample_spatial, to for instance EPSG:3035, to avoid working in multiple projections due to the native UTM projections being used.
It could however also be the case that this method which tries to compute the area has an issue, I even note that the original inputs is points, so we may need to look in that direction.
I logged an issue to follow up this one a bit further: