It actually works with openeo-dev.vito.be, however, the output seems wrong.
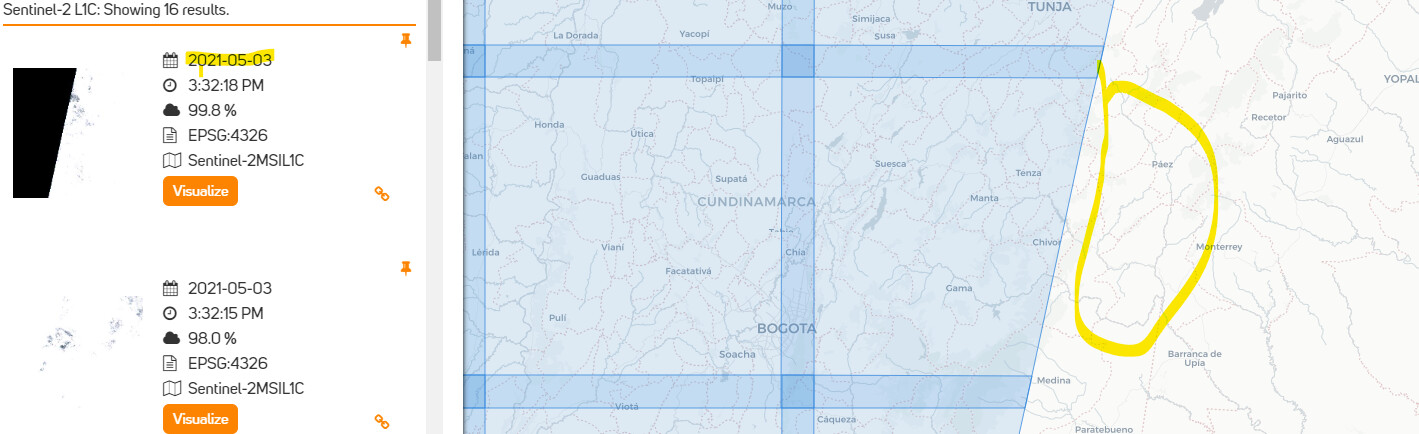
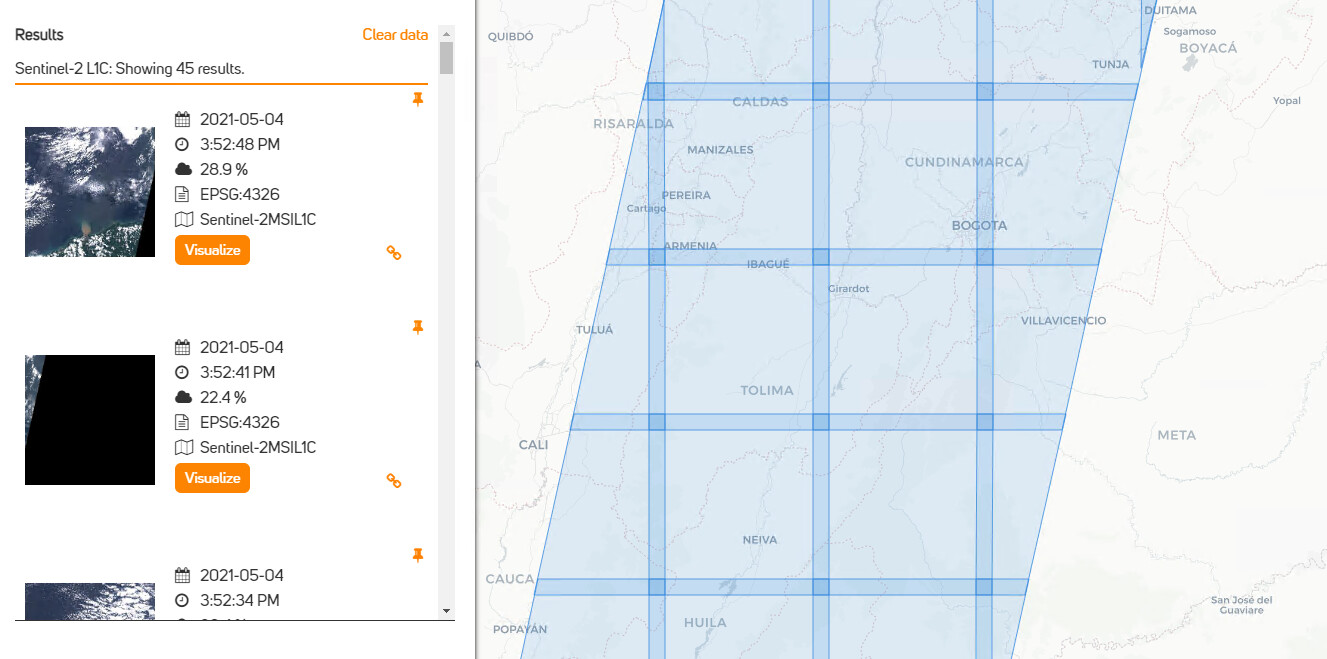
For example: S2, 2021-05-03, {‘west’: -74.5, ‘east’: -73, ‘south’: 4.5, ‘north’: 5, ‘crs’: ‘epsg:4326’}
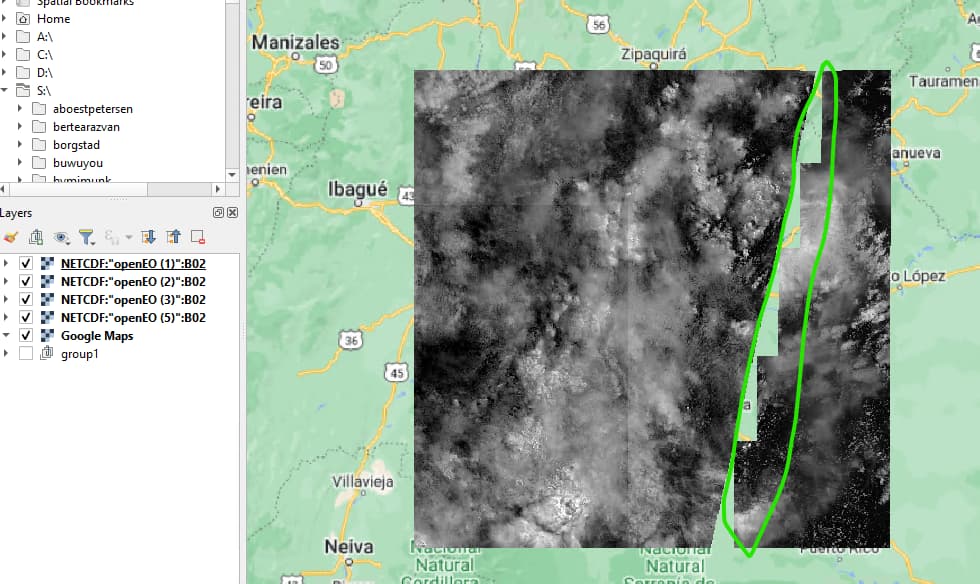
Online searching shows that S2 data should be only on the left site. The right site (a yellow mark) should not have any data for that day (2021-05-03). The S2 satellite did not over pass the right area.
I tried your code with a smaller bbox (to save on executio time), but so far I can not reproduce that problem: data is missing properly in my resulting netcdf for the areas that are not visited.
Features available on openeo-dev.vito.be become available on openeo.cloud eventually. What feature are you concerned about in particular?
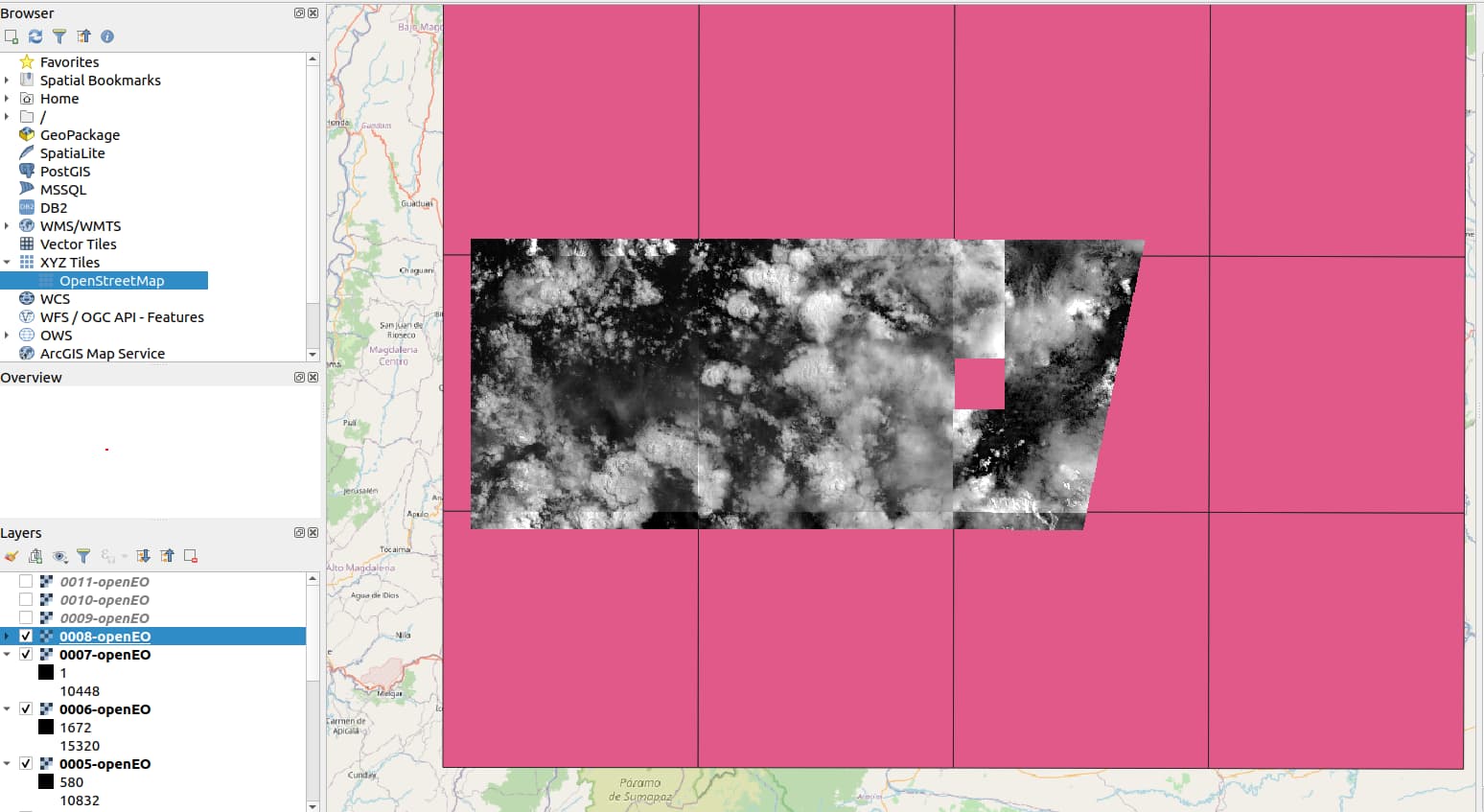
First of all, Outputs are the multiple nc files based on grid area. Is it possible to composite all files as a part of postprocessing when all sub-jobs are finished? It will be better for a user to get final product as one nc.file.
Secondly, I am getting the same gap problem as it was mentioned before. Can you try to run the same spatial and temporal extent?
This is an ouput for 2021-05-03 when all sub-files are loaded:
Those are really good reasons. However, If a user does not need any inspection as he/she is confident about correctness of results then it will be nice to have this option. Thus, What about to leave this decision on a user?
Maybe it will be reasonable to have a default option as “False” but if the user’s aim will be postprocessing, then it can be set to True as a part of job_options specification.
Hey Andrea,
I copy-pasted the code from your first post and only changed the temporal extent to [2021-04-28, 2021-05-08]. As a result I also receive 12 netCDF files (one for each tile).
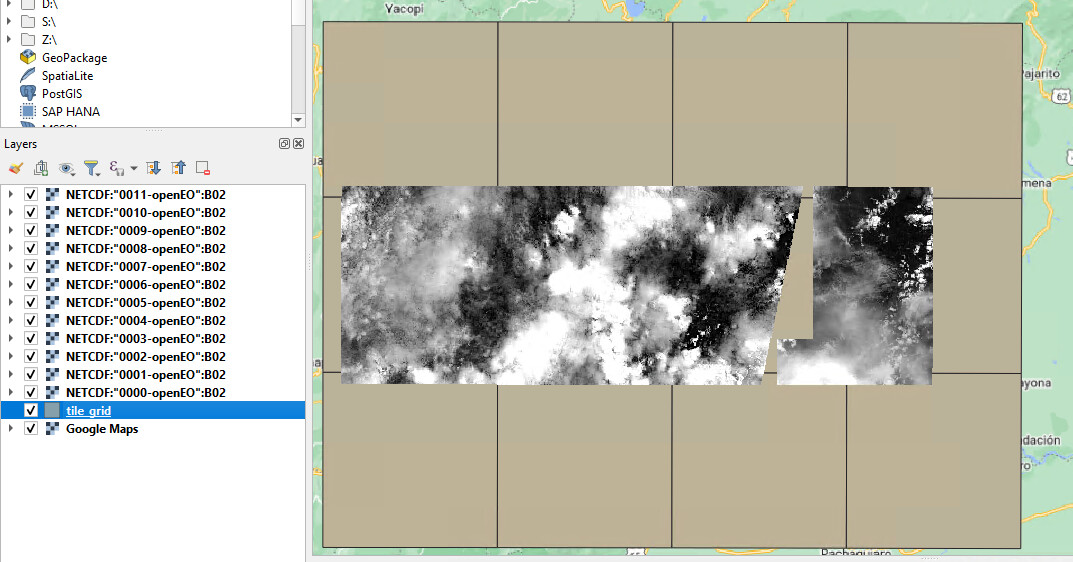
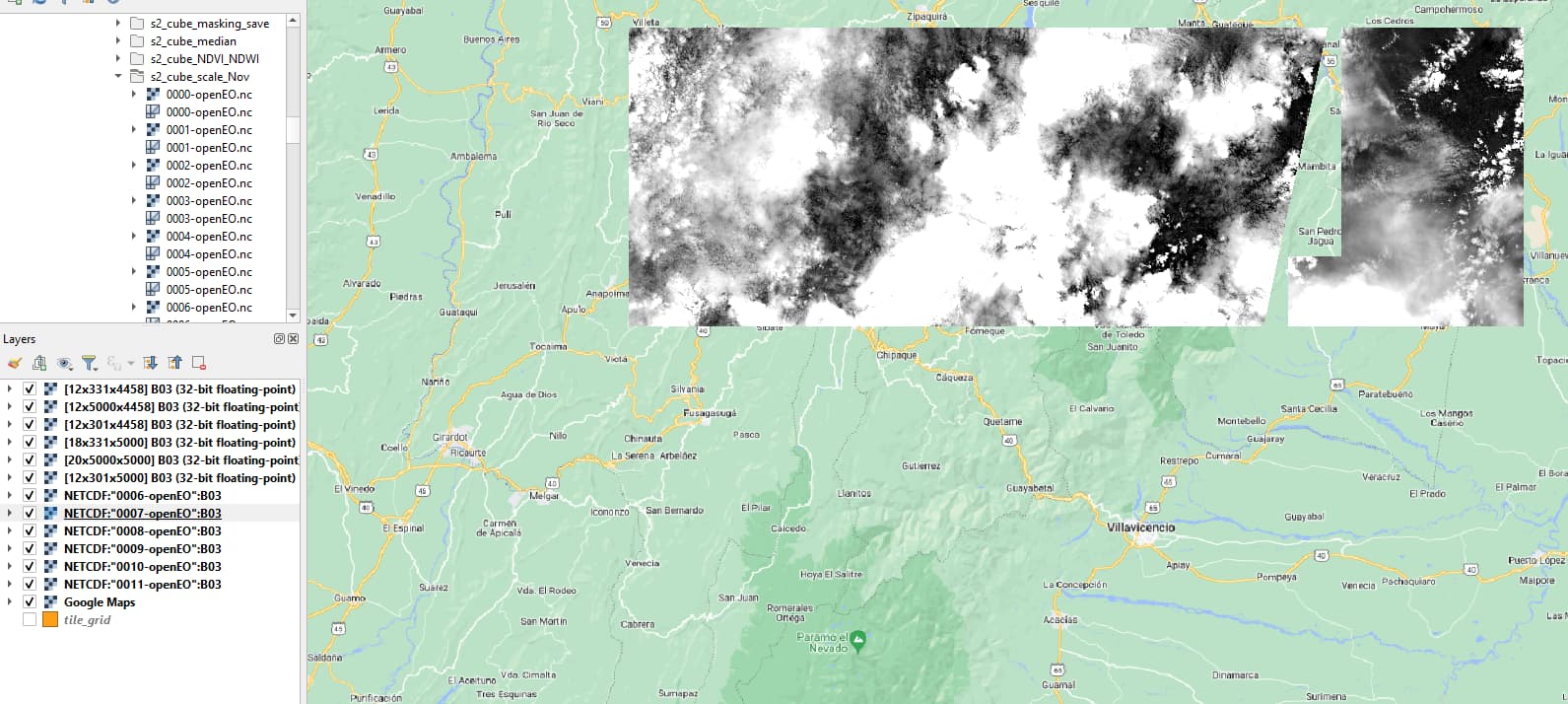
If I open these netCDF files in QGIS, each having a band rendering of singleband gray for t=11445 (=2021-05-03) I obtain this image:
There does appear to be something off with the tile in question though, similar artifacts occur when I look at the other dates.
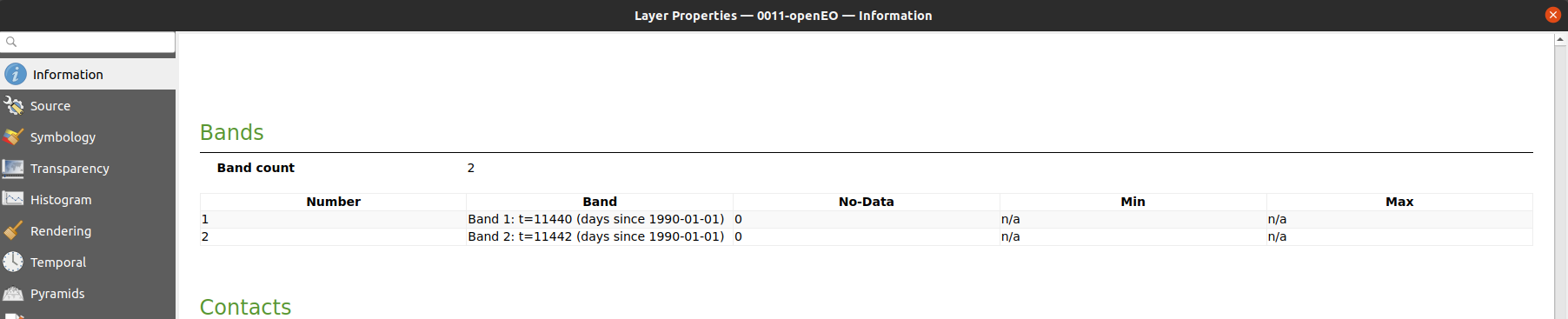
Are you sure that these three files have a band for t=11445 on your end? I just want to verify that on that topic there are no inconsistencies, then I have a better idea of the problem that needs to be solved.
I located the origin of the problem and created a new issue for it on Github:
In a nutshell, the VITO backend splits its request to SentinelHub into batches when the requested area is larger than 50x50 km², and there is an issue when these batches are stitched back together. This will be worked on as soon as possible and should be fixed in about two weeks.
For now, there are two ways to circumvent the issue.
You can tell the backend directly to not batch requests to SentinelHub:
job_options={“sentinel-hub”: {“input”: “sync”}}
You can use a tile grid on openeo.cloud with tiles smaller than 50x50 km²:
Eventually, I have obtained the ouput (after 7hours) usingopeneo-dev.vito.be and seems correct.
The ouput is also merged into one tile which is perfect. Thanks for fixing the problem!
Glad to see that you’re making progress. Some notes:
openeo.cloud points to our production environment and the fix I committed is currently only available on openeo-dev.vito.be, as you have noticed; we’ll do our best to get the fix on openeo.cloud as soon as possible;
please refrain from submitting the same job multiple times if they stay “queued” longer than usual; they will be handled eventually and submitting more jobs won’t make them run earlier (the opposite is true);
@jeroen.dries is on holiday this week but I took a look at the scene above and it seems that those “masks” are already visible in the source data: Sentinel Hub EO Browser; you might want to contact Sentinel Hub directly in case you have any questions regarding this behaviour.