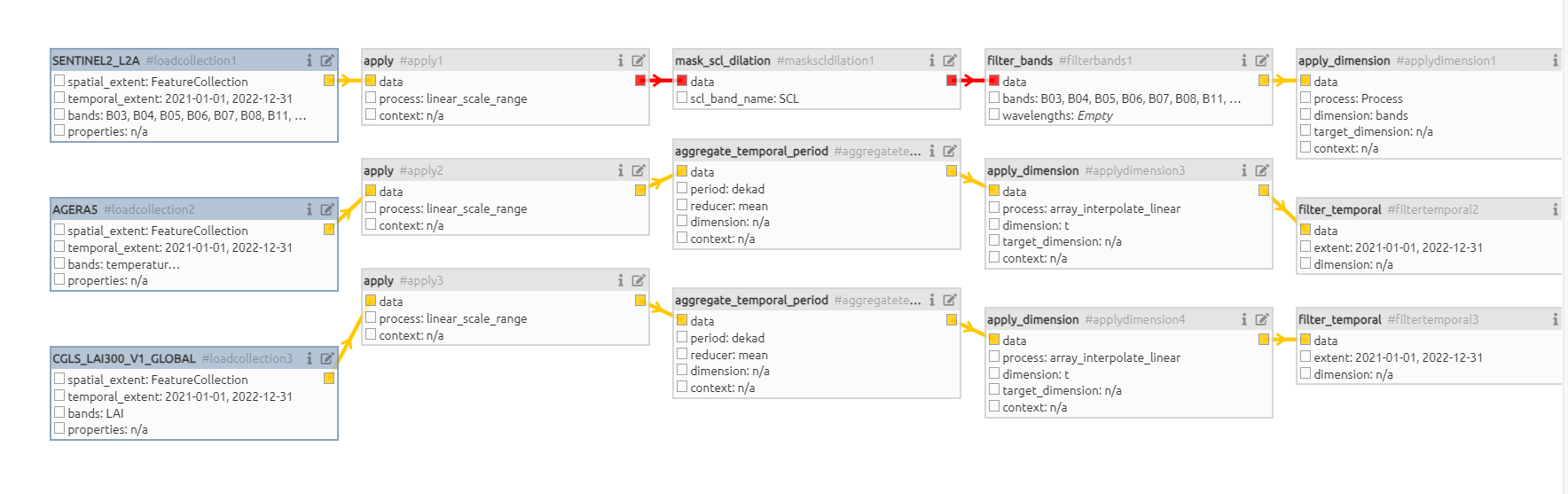
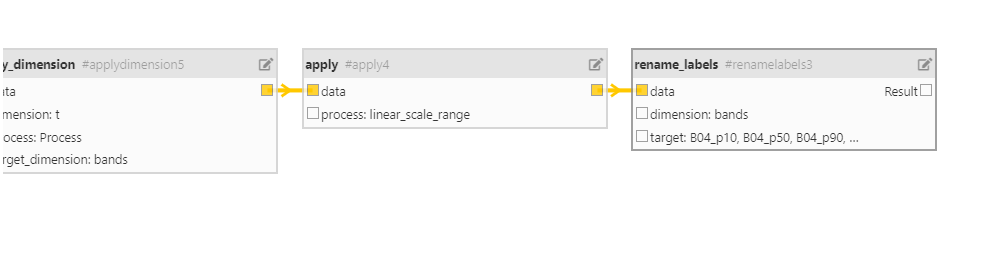
Hi,
I want to merge these collections and apply function to the merged one. But I am getting error saying ‘data type is not compatible’.
1:14:04 Job ‘j-240228f90e2b4916841696ee00d04abb’: error (progress N/A)
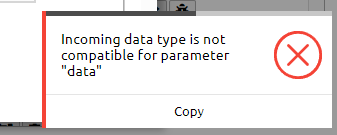
How can I manage this error?
Hi,
I want to merge these collections and apply function to the merged one. But I am getting error saying ‘data type is not compatible’.
1:14:04 Job ‘j-240228f90e2b4916841696ee00d04abb’: error (progress N/A)
How can I manage this error?
Hi,
this warning can be safely ignored, it will even be fixed in one of the upcoming releases.
The real error was an authentication token that expired because the job used sentinelhub but also took very long to load the data.
My suggestion would be to set a ‘max_cloud_cover’ in load_collection of SENTINEL2_L2A to 95 or lower. This would allow the backend to load data from terrascope, which does not have the very cloudy tiles.
Another thing to try is to simpy send fewer polygons or reduce the overall area that is covered by them, as this is now rather large.
Let us know if that still results in very long jobs!
Well, i reduced aoi, and set a cloud coverage to 70. But, still taking hrs to execute.
![]()
Hi,
indeed, I just checked, and there is no data directly on Terrascope for your area of interest, so the jobs will simply need a bit more time.
If you want it to go faster for testing purposes, you can consider trying an area in Europe and a time window in the last 2 years. This will also be cheaper. You can then run the final job in your desired AOI when it works.
I also noticed you are running on a smaller area to test, which is certainly a good idea.
Your jobs are also getting a bit further now, but go out of memory. I suspect this as something to do with the agera5 data which is resampled to 10m resolution.
There is a trick you can try to avoid going out of memory. It involves forcing the initial chunk size for agera5 to a lower value. The sample below sets it to 4, you can also try to lower until 1 if it still goes OOM.
ERA5_dc = connection.load_collection(
"AGERA5",
temporal_extent=["2015-01-01", "2023-07-01"],
spatial_extent={"west": 15, "south": -34, "east": 32, "north": -21, },
bands=["precipitation-flux"],
)
ERA5_dc._pg.arguments['featureflags'] = {"tilesize": 4}
Next to that, it is also possible to simply increase memory, which is explained on the page below. You’ll need to increase ‘executor-memory’ in this case, but do try staying below 16GB.
Hope this already helps. Your workflow is already quite big, so may take a bit of tuning to get right.
Thank you so much for the suggestions. I increased Job executor memory options from 2G to 4G. I am still struggling to extract information from labeled points. Also, unable to decode following error.
I think the service was effectively unreachable for a few minutes there, but your job should not be affected and you should still find results or error logs in the web editor at editor.openeo.cloud.