Data cubes with the dimensions x, y and t have the same dimension labels in x,y and t. There are two options:
Keep the overlapping values separately in the merged data cube: An overlap resolver is not needed, but for each data cube you need to add a new dimension using add_dimension. The new dimensions must be equal, except that the labels for the new dimensions must differ by name. The merged data cube has the same dimensions and labels as the original data cubes, plus the dimension added with add_dimension, which has the two dimension labels after the merge.
When not using an overlap resolver I get: java.lang.UnsupportedOperationException: The operator: null is not supported when merging cubes. Supported operators are: Set(subtract, min, divide, or, max, xor, multiply, add, sum, and, product).
When using an overlap resolver, I get: java.lang.IllegalArgumentException: Merging cubes with an overlap resolver is only supported when band counts are the same. I got: 4 and 1.
to merge the datacubes. I also tried overlap_resolver=None. The datacubes have different bands with the same xy resolution using resample_cube_spatial. Any ideas?
Could it be that you merge the optical cube with dims (x,y,t,bands) with a cube with only (x,y)?
It seems that this is not supported yet indeed.
Masking the optical cube with the water mask would be supported, but I guess that’s not what you’re after?
Please let me know how urgent this is, I believe we can add it.
This is the water occurrence dataset that I am looking to merge with optical (S2_L1C).
interesting that the occurrence band changes into 1 when downloading.
The context for this merge is that I want to use the water occurrence dataset in my UDF, so I am trying to merge that dataset into the optical data. I need this dataset for the waterwatch algorithm.
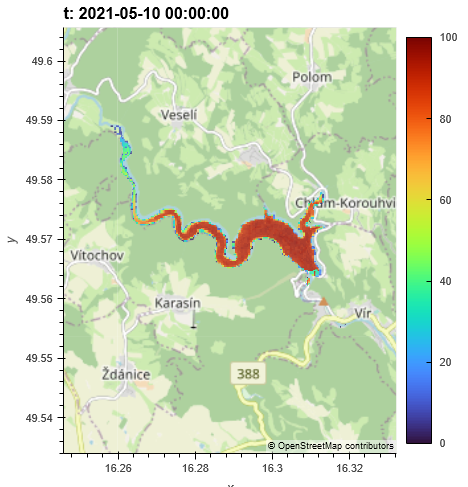
@jdries I went along with this using bands to merge the two datasets, just using the MNDWI (dimensions: ["x", "y", "t", "bands"] and the water occurrence dataset (dimensions: ["x", "y", "bands"]). Both bands dimensions have a length of one. This worked (I had to multiply the water occurrence dataset by 1.0 to go from int16 to float32 to make it work). Now I get some strange results. As expected, I have values for the wateroccurrence dataset for all t now. However after merging, some of the values for the water occurrence are removed:
This is of course unexprected, as the water occurrence dataset is present globally.
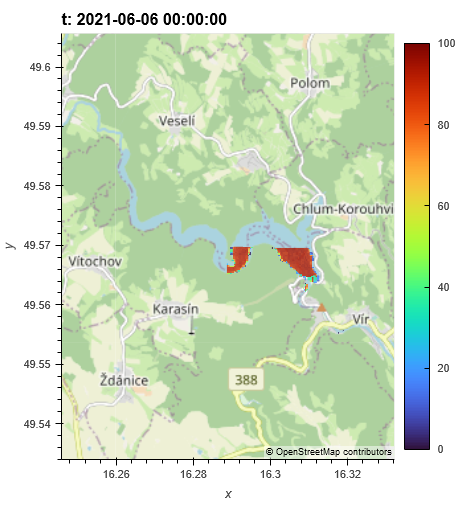
Missing data only happens on timesteps where the optical satellites only covered part of the area of interest.
Hi Jaap,
you’re right! I inspected the code, and found the issue below. One potential workaround (but haven’t tried it), is to use aggregate_temporal(_period), which has the side effect of inserting empty tiles at locations where no data is found.
For fixing the issue itself, can you give an indication of urgency?
@jeroen.dries I now realize that I do not have the time interval before sending the job, so this way I would have to split my workflow in two:
Load and filter optical data. Then download the data and check timestamps.
use timestamps from local to send a seconds job with the follow up steps.
So in terms of efficiency, it would be good to have the fix!
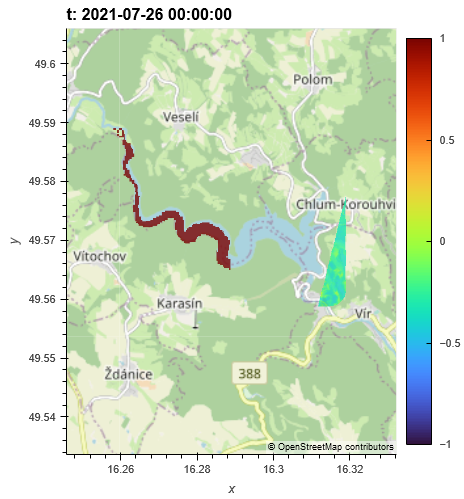
I tried the workaround. I used aggregate_temporal on the MNDWI DataCube. After this I did the merge with the water occurrence dataset. I am getting an interesting result:
The results now get mixed together. Missing tiles in the MNDWI cube are filled in using the wateroccurrence dataset.
Hi Jaap,
I’m looking into this one, have a partial fix already.
But now started to wonder what the plan is for areas where you don’t have an optical observation but you do have water occurance? Like just from a use case perspective, what will you do if you don’t have an observation anyway?
Or should we have a call on this?
@jeroen.dries When using chunk_polygon any way of distinguishing masked values (outside the polygon) from nodata values?
Also, how do I know which nodata type to expect in the XarrayDataCube?