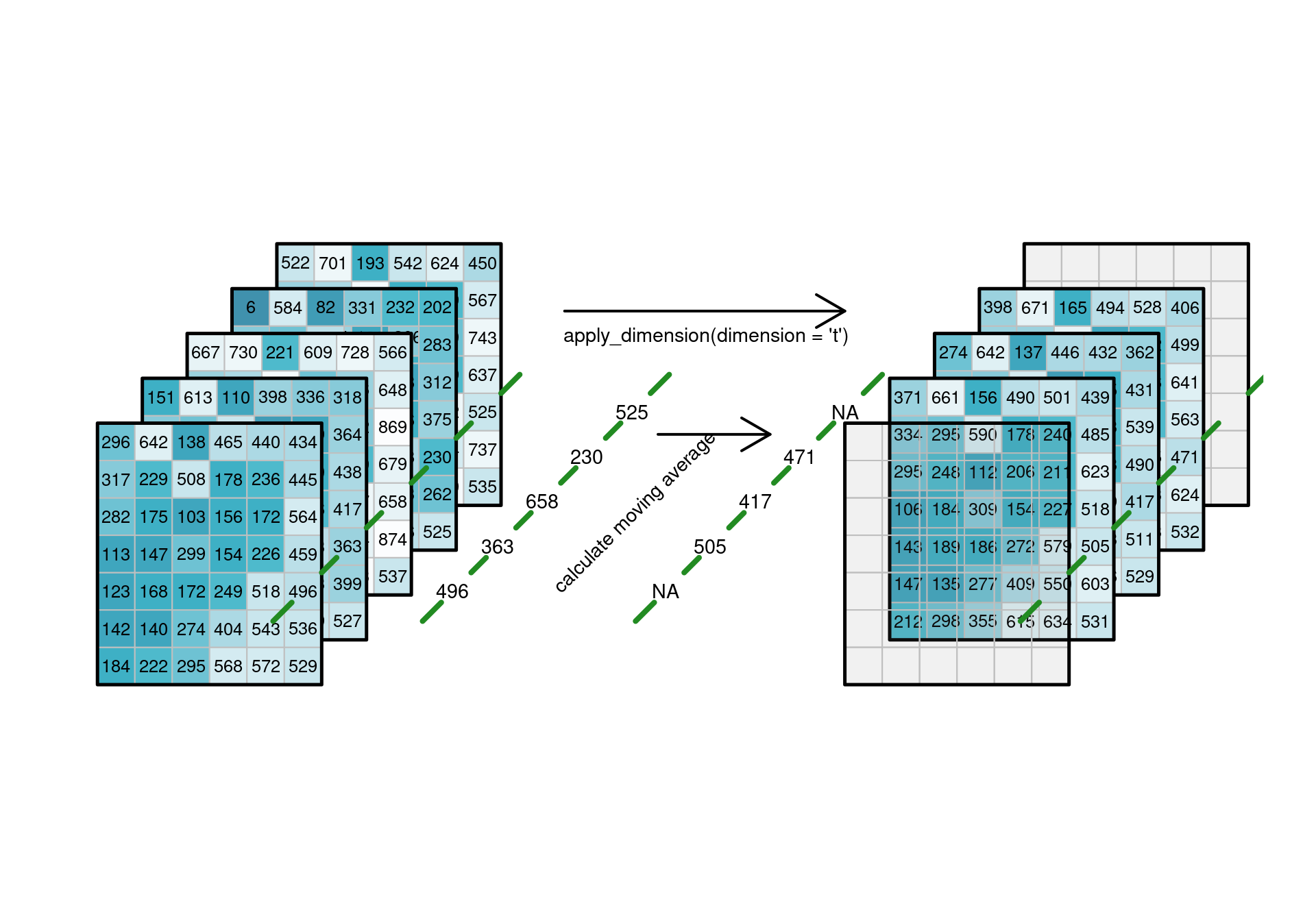
the function “moving_average” is not working for apply dimension. Do you have any ideas on how to implement this (this or any
other way)?
The image from Edzer’s book is the main reference for that and it should help find a solution…
In theory, but probably not yet supported, the ‘apply_neighourhood’ process allows you to apply a function, like mean, to a spatiotemporal window that you can specify.
What time window would you like to apply it to?
Actually I’m develoing an RShiny application that calls openEO processes. The time window would be user defined, but in general monthly / 3 months, something like that.
I gave a look with Matthias at the apply_neighborhood, but the problem is that it expects a two dimensional datacube, so this would not work for time (moving average).
I tried here passing a reduce_dimension process, but I’m not sure what’s the proposal for one dimension.
I’m not sure how this should look like with apply_neighborhood. If you pass only t as dimension then you’d work on a 1D data cube in the callback, but which process to use then? apply_dimension on t with a mean? This is somewhat weird…
Of course, this assumes that the backend is allowed to ‘flatten’ the input to mean into a one dimensional array. Would that be ok?
We can indeed support this on vito backend, but do need to plan the work, so due to holidays this could move into september.
@m.mohr is my proposal allowed by the spec?
I may need to do some work on our apply_neighborhood in the coming weeks in any case, could be an option to also consider this.
@jeroen.dries No. The process provides a raster-cube in the callback, which can’t be passed to mean.
Also, wouldn’t you need to set the size to 1x1x1 and then add an overlap to the temporal dimension? Then you could likely make it somehow work. But overall, this is so complicated and seems to be a candidate for a new process.
A little off topic… I haven’t looked at the process for quite a while, but I also see some contrary definitions there. On the one hand, the description says:
The process must not add new dimensions, or remove entire dimensions, but the result can have different dimension labels.
On the other hand, in other places it says:
The dimension properties (name, type, labels, reference system and resolution) must remain unchanged, otherwise a DataCubePropertiesImmutable exception will be thrown.
and
A data cube with the newly computed values and the same dimensions. The dimension properties (name, type, labels, reference system and resolution) remain unchanged.
Did we actually intend for this to pass datacubes into the callback? Very similar processes like apply_dimension also pass in a labeled array, which seems to make more sense as that is what allows our callback processes to work on it right?
You would indeed set size to 1x1x1 and set overlap in temporal dimension. Not sure why that is complicated? For backends, maintaining a large number of specialized processes is also complicated.
Yes, that is intentional. That’s how it is defined since the beginning because all array operations only work on 1D arrays and if you want to work on ND arrays you need to work on datacubes. Thus, apply_neighborhood is using datacubes in the callback.
What I’m not clear about when working with the process is: If you specify overlap, what is expected to be returned from the callback? the data with or without overlap?
It doesn’t feel very intuitive for such a simple use case and multiple people can’t come up with a solution so it seems it should be made possible?
apply_neighborhood is incompatible with most other processes that we typically use in callbacks, except perhaps for run_udf, which allows ‘any’ as data type. This is not impossible to solve, either by:
a) an explicit datacube to 1D array function
b) an rule that allows a backend to implicitly flatten a datacube into a 1D array when needed
some use cases that are covered by apply_neighborhood could be made simpler by having a specialized version with arguments set to fixed values, very much like we did in the CARD4L version of backscatter. This is mostly about convenience, which could also be taken care of in the clients, but it could be an option if the convenience process turns out to be popular.
apply_neighborhood description needs to better define overlap, that requires a ticket.
So basically, if we agree on 1-a or 1-b, we can help out this use case already, and follow up on 2 and 3 separately?