rmgu
29 June 2022 07:26
1
Hi,in another discussion ) but I cannot see the output either below the cell executing the UDF or in the job logs. See the code example below. What is the proper way to do this?
udf_code = """
from openeo.udf import XarrayDataCube
def apply_datacube(cube: XarrayDataCube, context: dict) -> XarrayDataCube:
print("test")
return cube
"""
process = openeo.UDF(code=udf_code, runtime="Python", data={"from_parameter": "x"})
out_cube = in_cube.apply(process=process)
my_job = out_cube.send_job(title="test")
results = my_job.start_and_wait().get_results()
0:00:00 Job 'j-f6c5c0e454314179b205c5cb6f80efed': send 'start'
0:00:24 Job 'j-f6c5c0e454314179b205c5cb6f80efed': queued (progress N/A)
0:00:29 Job 'j-f6c5c0e454314179b205c5cb6f80efed': queued (progress N/A)
0:00:36 Job 'j-f6c5c0e454314179b205c5cb6f80efed': queued (progress N/A)
0:00:44 Job 'j-f6c5c0e454314179b205c5cb6f80efed': queued (progress N/A)
0:00:54 Job 'j-f6c5c0e454314179b205c5cb6f80efed': queued (progress N/A)
0:01:07 Job 'j-f6c5c0e454314179b205c5cb6f80efed': queued (progress N/A)
0:01:23 Job 'j-f6c5c0e454314179b205c5cb6f80efed': queued (progress N/A)
0:01:42 Job 'j-f6c5c0e454314179b205c5cb6f80efed': running (progress N/A)
0:02:06 Job 'j-f6c5c0e454314179b205c5cb6f80efed': running (progress N/A)
0:02:37 Job 'j-f6c5c0e454314179b205c5cb6f80efed': running (progress N/A)
0:03:14 Job 'j-f6c5c0e454314179b205c5cb6f80efed': running (progress N/A)
0:04:01 Job 'j-f6c5c0e454314179b205c5cb6f80efed': running (progress N/A)
0:04:59 Job 'j-f6c5c0e454314179b205c5cb6f80efed': finished (progress N/A)
print(my_job.logs())
[]
1 Like
Indeed, this feature (logging from UDFs) does not work yet the way we want it at the moment.
rmgu
18 August 2022 08:45
3
Hi Stefaan, would you have any update on the progress of UDF logging?
So far we don’t have anything working for end users.
Hi,
I wanted to let know that we have initial support for logging from UDF’s for debugging purposes.
usage example:inspect logging function (based on inspect process
from openeo.udf import XarrayDataCube
from openeo.udf.debug import inspect
def apply_datacube(cube: XarrayDataCube, context: dict) -> XarrayDataCube:
inspect(message="Hello UDF logging")
inspect(data=[1,2,3], message="hello UDF logging with data")
array = cube.get_array()
array.values = 0.0001 * array.values
return cube
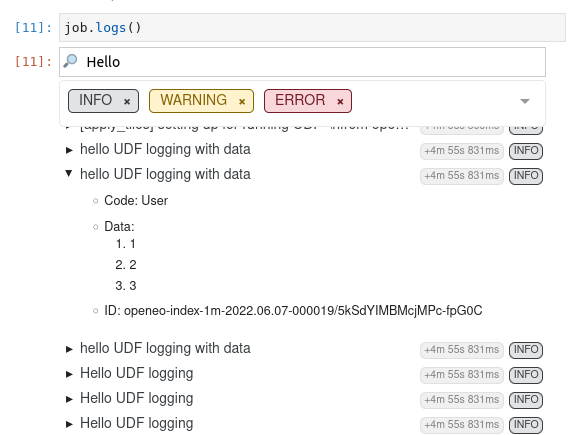
When requesting the job logs, you should be able to see these log entries, for example in a Jupyter notebook using the job.logs() widget:
At the moment, not all data types are properly supported in the data argument of inspect, we are working on that. But feel free to already experiment with the current functionality
1 Like
Hi, thank you for this feature. Do I need to use a development version of openEO or does the latest release (0.23.0) already contain the logging capability?
Hi,
Note that the UDF runs backend-side, so this feature does not really depend on what version of the python client you are using on your system.
thanks you for the precision, I’m discovering openEO and I’m trying to do some logging. Here is the code I’m using
import openeo
connection = openeo.connect("openeo.vito.be")
connection.authenticate_oidc()
collections = connection.list_collection_ids()
sentinel2_cube = connection.load_collection(
"SENTINEL2_L2A",
spatial_extent={"west": 5.14, "south": 51.17, "east": 5.17, "north": 51.19},
temporal_extent=["2021-02-01", "2021-04-30"],
bands=["B02", "B04", "B08"],
)
blue = sentinel2_cube.band("B02") * 0.0001
red = sentinel2_cube.band("B04") * 0.0001
nir = sentinel2_cube.band("B08") * 0.0001
evi_cube = 2.5 * (nir - red) / (nir + 6.0 * red - 7.5 * blue + 1.0)
udf = openeo.UDF(
"""
from openeo.udf import XarrayDataCube
from openeo.udf.debug import inspect
def apply_datacube(cube: XarrayDataCube, context: dict) -> XarrayDataCube:
inspect(message="Hello UDF logging")
inspect(data=[1,2,3], message="hello UDF logging with data")
array = cube.get_array()
array.values = 0.0001 * array.values
return cube
"""
)
evi_cube.apply(process=udf)
inf_job = evi_cube.execute_batch(out_format="GTiff")
inf_job.get_results().download_files("/somewhere/")
print(inf_job.logs())
But nothing seems related to my UDF logs. I can provide the job id : j-09480bffb3df4ad28d402fdcc1c01ce8. Do you need extra informations ?
quick note (I’m not sure it is root cause)
you need evi_cube = evi_cube.apply(process=udf) there, otherwise that line doesn’t have any effect
FYI: this snippet works for me regarding the inspect logging:
# imports and `connect` stuff omitted
cube = connection.load_collection(
"SENTINEL2_L2A",
spatial_extent={"west": 5.11, "south": 51.11, "east": 5.12, "north": 51.12},
temporal_extent=["2021-02-01", "2021-02-20"],
bands=["B02", "B04"],
)
udf = openeo.UDF(
"""
from openeo.udf import XarrayDataCube
from openeo.udf.debug import inspect
def apply_datacube(cube: XarrayDataCube, context: dict) -> XarrayDataCube:
inspect(message="Hello UDF logging")
inspect(data=[1,2,3], message="Hello UDF logging with data")
array = cube.get_array()
array.values = 0.0001 * array.values
return cube
"""
)
cube = cube.apply(process=udf)
job = cube.execute_batch()
There is the problem of poor signal/noise ratio of the logs, but I created a ticket for that at Improve signal noise ratio of batch job logs · Issue #538 · Open-EO/openeo-geopyspark-driver · GitHub
Thank’s you for your quick reply, I updated my code as
import openeo
connection = openeo.connect("openeo.vito.be")
connection.authenticate_oidc()
collections = connection.list_collection_ids()
sentinel2_cube = connection.load_collection(
"SENTINEL2_L2A",
spatial_extent={"west": 5.14, "south": 51.17, "east": 5.17, "north": 51.19},
temporal_extent=["2021-02-01", "2021-04-30"],
bands=["B02", "B04", "B08"],
)
blue = sentinel2_cube.band("B02") * 0.0001
red = sentinel2_cube.band("B04") * 0.0001
nir = sentinel2_cube.band("B08") * 0.0001
evi_cube = 2.5 * (nir - red) / (nir + 6.0 * red - 7.5 * blue + 1.0)
udf = openeo.UDF(
"""
from openeo.udf import XarrayDataCube
from openeo.udf.debug import inspect
def apply_datacube(cube: XarrayDataCube, context: dict) -> XarrayDataCube:
inspect(message="Hello UDF logging")
inspect(data=[1,2,3], message="hello UDF logging with data")
array = cube.get_array()
array.values = 0.0001 * array.values
return cube
"""
)
out_cube = evi_cube.apply(process=udf)
my_job = out_cube.send_job(title="test")
results = my_job.start_and_wait().get_results()
print(my_job.logs())
I’m no longer using “execute_batch” and I’m not downloading files. However the job fails with the ID j-650d652afc8c4ca5a275707ef95422cb
I managed to get some logs with your example. However, once you introduce calculations on the cube as follows
blue = sentinel2_cube.band("B02") * 0.0001
red = sentinel2_cube.band("B04") * 0.0001
nir = sentinel2_cube.band("B08") * 0.0001
evi_cube = 2.5 * (nir - red) / (nir + 6.0 * red - 7.5 * blue + 1.0)
the job fails. Have you succeeded in reproducing this behaviour?
you stumbled on a bug, for which I created a ticket here: UDF failure on cube without bands dimension · Issue #539 · Open-EO/openeo-geopyspark-driver · GitHub
workaround is to add a “bands” dimension before applying the UDF.
evi_cube = evi_cube.add_dimension(name="bands", label="evi", type="bands")
thanks you for creating the issue and for suggesting the workaround ! I’ll keep an eye on the issue.