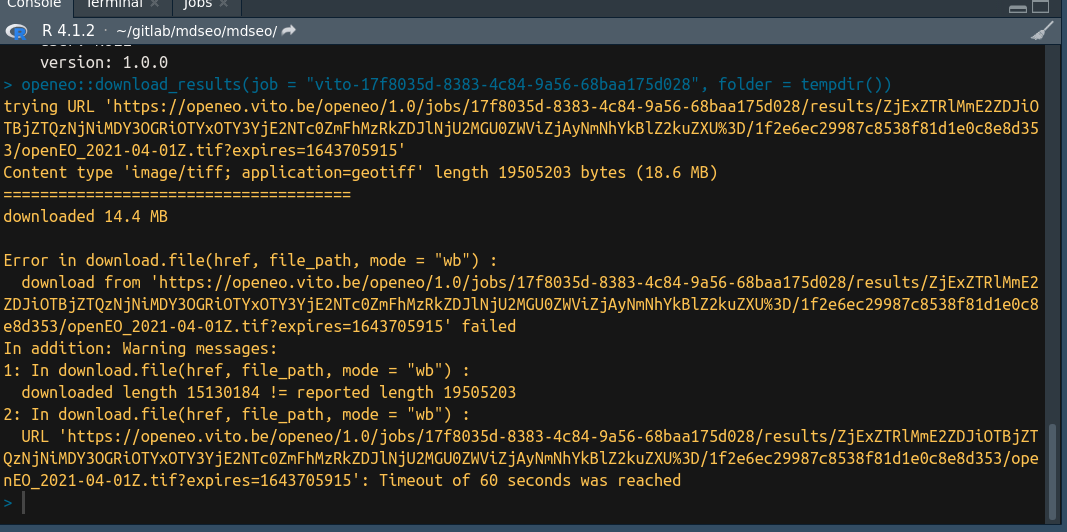
when trying to download a job result (2 tifs, size of around 18MB) the download was aborted halfway through with the message “Timeout of 60 seconds was reached”.
I realize that is probably due to my very bad internet connection in homeoffice, but 60 seconds seems short in any case.
Is there a way to increase this time limit or maybe put a limit on size instead?
Can you also give more info about the error message? For example: do you have a full stack trace? Or a screenshot of some more context around the error message?
thanks for the quick response and sorry it took this long to react to it.
I had thought this was a “built-in” error in the sense that the timeout was coded in
consciously. Thus I had not thought to take any screenshots and had to wait for my internet connection to be bad enough again for the error to re-occur.
In any case, this is the full message:
I hope this helps. I will also edit the post to include the R-client tag. As I said above, this is not an urgent problem seeing as it is really only dependent on the internet connection quality in this case. However, for larger downloads 60 seconds might be short even if the connection is better.
Best!
currently I am using download.file() for downloading the data. Your error states a timeout on the client side of 60s. Looking at the manual it says that they use a default timeout of 60s. As a quick fix, you can change it by setting a different timeout with options(timeout = <value>).
For the long run, I will have another look at this and rework this at time.